
WWDCも終わり、各社のAI戦略が一通りできったところで、5月上旬に発表された「Apple M4」の考察でもしてみようとおもう。AI時代もAI時代なので、Appleがどういうアプローチをしているのかを確認したい。
Apple M4
Apple M4は、Apple Siliconでは久々のメジャーアップデートに近いものになったという印象がある。基本的にA14/M1世代から、M2・M3と比較的小規模なアップデートが続いたが、M4はやや大きめのアップデートと言える。とはいっても、A12ほどのアップデートかと言われればそうではない。ただ最近のAppleにしては大きめのアップデートだったという印象だ。
今回、Apple M4で目に見えて強化されたものはCPUとNeural Engineである。ともにAIを意識した変更点もあるだろう。
CPU
まず、CPUから見ていく。
Apple SiliconのCPUは、Arm ISAを利用した独自設計のCPUである。そのため、CortexのようにArm ISAで完全に整えなければならないというわけではない。つまり、あとから特殊命令を追加することが可能。更にAppleはOSというソフトウェア側のプラットフォームも独自で有しているため、Apple Siliconを最大限活用できる。
結果としてAppleは、Armのマトリックス演算命令のSME(Scalable Matrix Extension)を好まず、独自でAMX(Apple Matrix Extension?)を実装していた。ただ、AppleはAMXの存在を公式には明らかにしておらず、おそらくApple製のAPIを利用しなければたたけない命令であると思われた。
その結果として、デファクトであるSMEを採用しているワークフローにおいてApple SiliconはそのCPUパワーのみで処理していたということになり、効率が悪かった。
SMEはArmv9の標準であったため、2021年にArmv9が登場した以降もAppleは頑なにArmv8系統を使い続けた。しかし、ようやくAppleはM4においてArmv9の採用へと踏み切った。おそらくこれは、AppleがArmv9に対してAMXの仕様かどうかは不明であるが、アップストリームした結果、SMEがAppleが望む仕様にアップグレードされたためであると考えられている。
Apple M4がArmv9に対応したことにより、CPUにはSMEを処理するためのアクセラレータが追加されたはずだ。Appleが「次世代のAIアクセラレータ」と表現しているのは、AMXアクセラレータがSMEアクセラレータにアップデートされたということを指していると思われる。
この結果として、SMEを採用するワークフローにおいて顕著な性能向上を達成した。
もちろん、SMEが利用できる例というのはAIだけではない。かつてのAVX-512の一部のバリアントがグラフィックスの描画性能の向上に寄与したように、SMEもAI以外の各種ワークロードの性能向上に寄与するだろう。
GPU
続いてGPUをみよう。
GPUにおいては、M4でこれといった大きなアップデートはない。対して前世代のM3は大きなアップデートとなった。M3からM4は半年程度でアップデートされたため、実質同世代として扱うことにしよう。
M3のGPUにおいては「レイトレーシング」「メッシュシェーディング」の対応が追加された。またMetal 3では、DirectXでの「Direct Storage」にあたる「Fast Resource Loading」などが追加された。このようなMetal 3の強化も相まってWindowsのDirectX 12 Ultimateに搭載されている機能や技術への対応が進み、M3ではゲーム面での進化が強調された。
Appleは数年前よりMacでのゲーミングに注力しており、WWDC 22以降、CAPCOM、コジマプロダクション、ubisoftといった著名なゲーム企業から著名な開発者を招待し、基調講演で声明を公開している。
実際、バイオハザードがMacやiPhone/iPadに対応したことや、DEATH STRANDINGのMacへの対応が行われ、今年にはさらにパルワールドなどもMacに対応する。このようなWindows向けゲームのAppleデバイスへの対応において、AppleはGame Porting ToolKit(GPTK)の提供を行っており、今年にはXcodeに対応したGPTK 2が登場した。Xcodeに対応することによってWindows向けゲームのiPhone/iPadへの対応も支援する方針だ。
と長々とゲーム面での進化を語ったが、実はAppleはGPUにおいてさほどAIへの言及を行っていない。おそらく、Neural Engineを使用してほしいという思いもあるのだろうが、基本的にAIのフル性能はパッケージ全体の性能(CPU+GPU+NPU)の性能で語られる。特にNPUとGPUはこのパッケージ全体の性能の内9割以上を占めることが多いため、GPUは捨てられないのだ。
一方でAppleは、AIの性能をNeural Engineでしか語らない。しかしこれは、AppleがAIにおいてGPUを捨てているというわけではない。言及が少ないだけでAIに対するGPUの使用の推進をソフトウェアの面からも進めている。
例えば、Appleの機械学習環境であるCoreMLはGPUを使うことが前提だ。必要に応じてNeural Engineを使う。AI処理に使われるユニットは、その演算のフォーマットや形式、必要とする能力などに応じて、適宜Apple Siliconが判断して効率的な処理を実現する。これは、MicrosoftのWinMLやAndroidでも同じである。基本GPUが前提で、NPUがあればNPUも使うという設計になっている。
更に、MetalではGPUによるコンピューティングのリソースも提供している。AIだけでなくシミュレーションなどのワークロードに対してもAPIを提供している。そして、Apple GPUは最近PyTorchのGPUアクセラレーションにも対応した。
AppleはGPUの性能についてそれほど多くは語らない。IntelのようにDP4a命令に対応したりXMXが・・・なんて言ってくれればわかりすいのだが。
ただ、Appleの場合、IntelやAMDよりもCPUとGPU、NPUの統合が進む。そのため、CPUとGPUそれぞれにAIのアクセラレータを搭載しなくともいいような気もする。
と、M4から話がそれているが、GPUはハードよりもソフトでの強化が中心だったような気がするため、これでしめる。
メモリ
Neural Engineの話をする前にM4でのメモリの進化点を捉えておきたい。
先ほどGPUの強化点をはなしたが、M3で「Dynamic Caching」が搭載された。これはどういったものかというと、メモリのGPUによる確保を動的に行うというものだ。
これはAIや機械学習の性能に直接的な影響を与えるものではないものの、Apple Siliconでは非常に重要である。
Apple Siliconはある面でみるとAIの研究に向いている。それがメモリだ。ユニファイドメモリアーキテクチャという関係上、メインメモリをビデオメモリとして扱うことが可能である。もちろん100%のメモリをビデオメモリに転用することはできないが、それでもメモリの大多数をビデオメモリに転用できるということには変わりない。
大規模なAIモデルを動作させる時、実はビデオメモリの大きさは重要である。推論を行うメインのプロセッサは基本的にGPUとNPUである。その部分のメモリというのは増やそうにも限度がある。コンシューマ向けでビデオメモリが最も多いのはGeForce RTX 4090の24GBである。プロ向けに目を向けると、RTX 5000 Adaが32GB、RTX 6000 Adaが48GBのメモリを有しているが、それ以上はないし、そもそもRTX 5000 Adaが80万円程度、RTX 6000 Adaが120万円程度となっている。
一方で、Apple Siliconでは、M4は16GBが現状最大であるものの、M2 Ultraで最大192GBのメモリを実現することができ、M4で同等のチップがでてくるのであれば、192GBやそれよりも大きいメモリを実現することができ、コスパよく大規模なモデルを扱うことができるというところから人気がある。
さらにM4では若干メモリが高速化している。120 GB/sとなっているのは、おそらくLPDDR5x-8500の採用が行われたからであろう。
もしこのままM4 Ultraまでスケールアップすると、1TB/s以上(1,088 GB/s)のメモリ帯域を実現することになり、最近のHBMには及ばないもののGDDR以上のメモリ帯域を実現することになり、AI演算において有利となるだろう。
Neural Engine
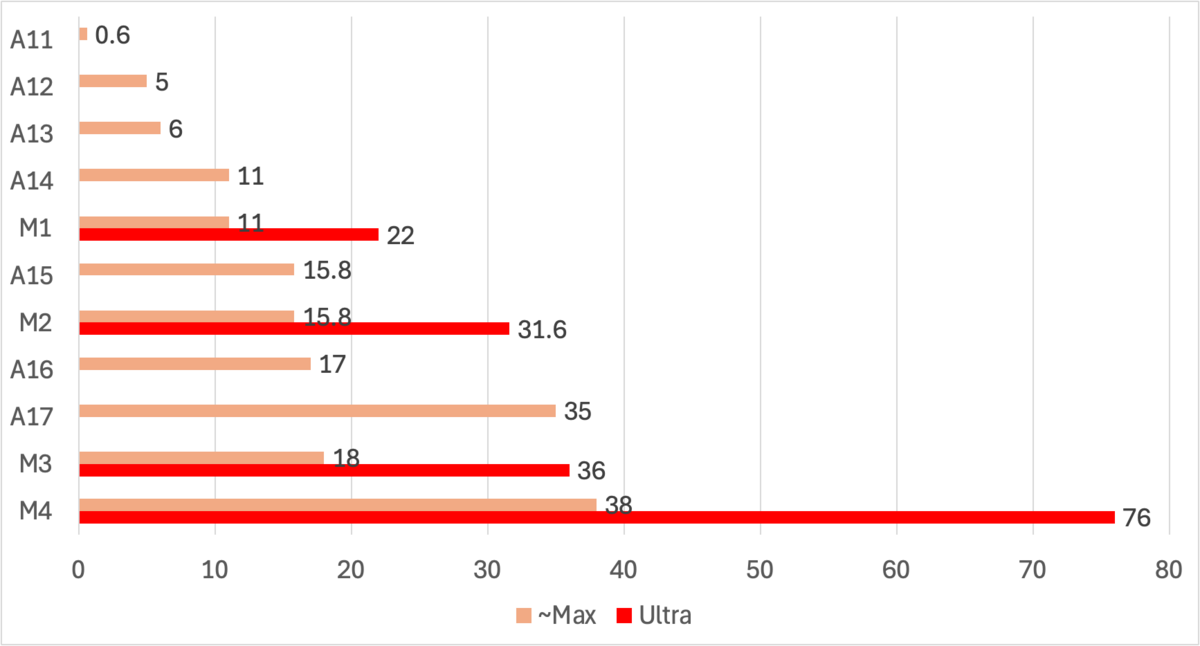
Neural Engineに目を向けよう。
Neural Engineは、M3の18 TOPSから2倍以上の進化なり、過去最大の性能向上となる38 TOPSを実現した。
2倍以上の性能向上の要因としては「コア数が同じであるためクロックを2倍以上に引き上げた」、あるいは「より低精度での演算に対応したか」のいずれかになる。おそらく後者だろう。
これまで、Neural Engineは対応する演算フォーマットについて公表されたことはないしわからない。そのため、M4のNeural Engineが何のフォーマットに対応したかは不明である。考えられるものはFP4やFP8のようなものだ。Apple Siliconはトレーニングよりも推論に注力していると考えられるため、これまでのNeural Engineよりも低精度のフォーマットをサポートしている可能性は高い。
WWDC21(iOS 15)の時点でCoreMLがNeural EngineにてFloat16での演算をネイティブとして行っていたことから、もともとFP16あるいはTF16のフォーマットをサポートしていた可能性は高い。と考えれば、M4ではFP8演算に対応したのではないだろうか。
ただ、語弊はあるものの余り精度を気にしなくてもいいのはCoreMLがいい感じにそのあたりを対応してくれているからだろう。ただ、MLPackageは私が確認している限りmacOS SequoiaやiOS 18でFloat16からフォーマットは変わっていないようだ。
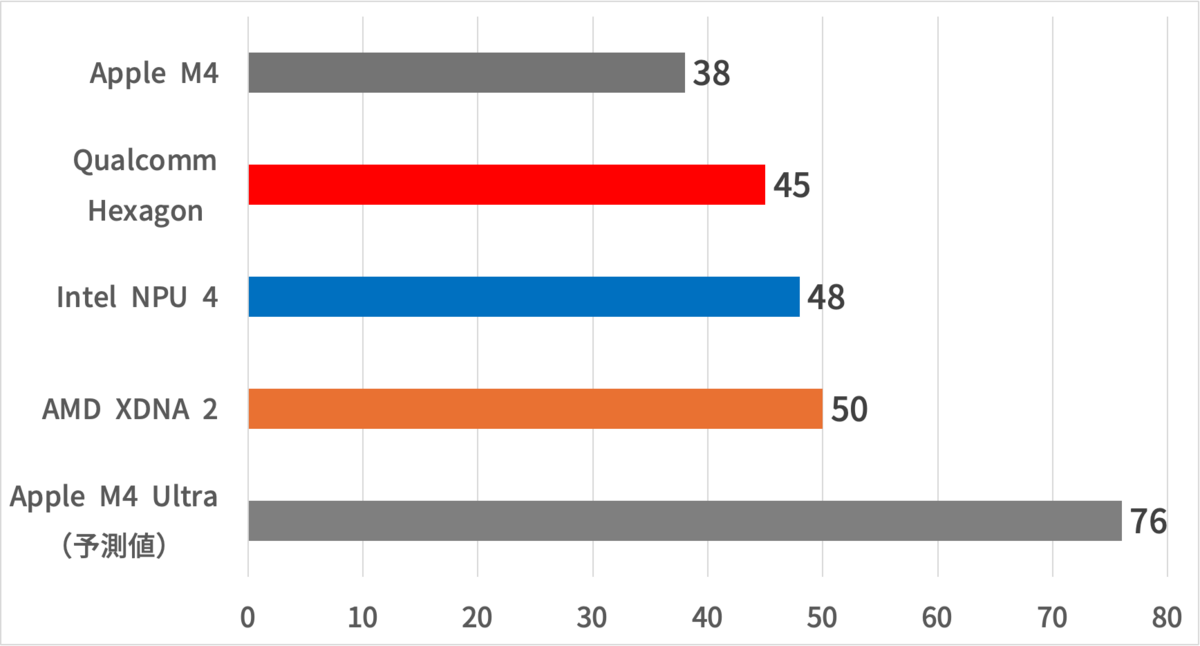
では、M4に限らず、M4 Familyに広げて性能という面をみてみよう。
38 TOPSという性能自体はとても低いというわけではない。ただし、登場したプロセッサ内蔵NPUとしては、比較的低い。そもそもAppleは、QualcommやIntel、AMDと違って、MicrosoftのCopilot+PCに適合する必要がないので比較的自由に設計できる。
他方で、今後M4がスケールアップして登場するとなると、おそらくNeural Engineのコア数も2倍の32コアになってくるM4 Ultraが登場する可能性がある。となれば、Neural Engineの性能は76 TOPSとなり、首位のAMDと大差をつけて勝利することとなる。
ただし、ここで一つ問題なのが、M4 Ultraが投入されるセグメントである。M4 Ultraと競合するセグメントには、NVIDIA GPUがあり、CPU内蔵のNPUと異なるため機能やターゲットに若干の差異はあるものの、数百TOPSの性能をもつワークステーションが相手ということになる。これには劣る。
これを解決する方法として考えられるのは、やはりGPUやNPUの独立である。もちろんこれをすることで、Appleのユニファイドメモリのメリットが失われてしまうが、性能を高めることはできるだろう。
そもそも、オールインワンのチップというのは、設計の効率化などのメリットはあるものの、ハイエンド向けのセグメントでは、各ユニットの規模を大きくできないという問題をはらんでいる。Appleがもしマルチチップレットを採用する予定ではないのであれば、しばらくこの問題は引きずることになるだろう。
期待することといえば、Mac ProでディスクリートGPUをサポートすることだが、PCIeがそもそもメモリの帯域よりも小さいため結局、UMAのメリットを享受できなくなる。
それ以外といえば、パッケージ間のUltra Fusionのような高速インターコネクトを活用して、CPUやメモリ、Display Engineなどのエンジンのパッケージと、GPUやNeural Engineのパッケージに分けることができれば、面白くかつ高性能なシステムが出来上がると考えるが、どうかな・・・。
〆
iPad ProとM4の発表、そしてApple Intelligenceが異例の2ヶ月連続のイベントで発表されたが、今回はM4について特集した。次はApple Intelligenceのアーキテクチャについてご紹介するので乞うご期待。
関連リンク
- A14 BionicのMetal性能の向上について - Tech Talks - ビデオ - Apple Developer
- Core MLを使用してデバイス上に機械学習モデルとAIモデルをデプロイ - WWDC24 - ビデオ - Apple Developer
- Training a neural network to recognize digits | Apple Developer Documentation
- 機械学習とAIモデルをAppleシリコンに統合 - WWDC24 - ビデオ - Apple Developer
- Appleプラットフォームでの機械学習の詳細 - WWDC24 - ビデオ - Apple Developer